Wir haben 2 neue Features für Sie eingebaut, es ist nun dadurch möglich Artikel inklusive Langtexten und Bildern einzulesen dieses betrifft die folgenden Felder:
| Zielspalte | Beschriftung der GUI |
|---|---|
| L_TXTFILE1 | Text 1 |
| L_TXTFILE2 | Text 2 |
| L_IDMEDIA1 | Bild 1 |
| L_IDMEDIA2 | Bild 2 |
Was hat sich bei Text 1 & 2 geändert?
Bei den L_TXTFILE1 & 2 ist es nun so, dass wir den Inhalt der zugewiesenen Zelle nehmen und wie folgt verarbeiten:
Nachfolgendes Beispiel erstellt eine Textdatei mit dem Inhalt und speichert die Datei in unserer dbFakt Umgebung ab und verknüpft dieses auf Text 1 beim Artikel 10001
l_nummer;l_txtfile1
"10001";"Dies ist ein langer Beschreibungstext welcher auch Umbrüche haben kann
dazu ist aber auch wichtig das dieser mit einer Texterkennung versehen ist" Nachfolgendes Beispiel kopiert die Textdatei von dem UNC Pfad und speichert diese in unserer dbFakt Umgebung ab und verknüpft dieses auf Text 1 beim Artikel 10001
l_nummer;l_txtfile1
10001;\\servername\freigabename\ordner\textdatei.txt Nachfolgendes Beispiel kopiert die Textdatei von dem absoluten Pfad und speichert diese in unserer dbFakt Umgebung ab und verknüpft dieses auf Text 1 beim Artikel 10001
l_nummer;l_txtfile1
10001;c:\benutzer\downloads\textdatei.txt Nachfolgend die Erklärung wie der Dateiname, der neu erstellten Datei, sich zusammen setzt
| Aufbau | Beispiel & Erklärung |
|---|---|
| Artikelnummer | 10001 |
| + | |
| Extension | _1 (diese ist fortlaufend, wenn bereits eine Datei gleichlautend im Textpfad vorhanden ist) |
| + | |
| Dateiextension | .txt |
| Ergebnis | 10001_1.txt |

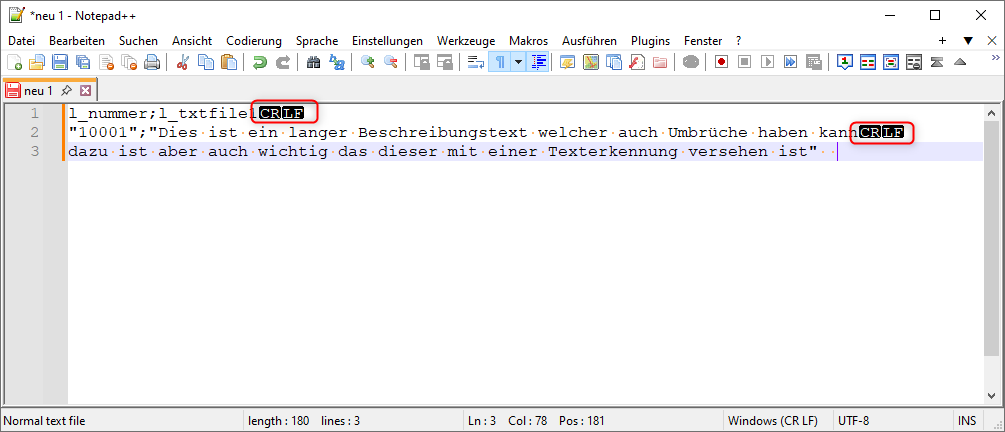
Achten Sie insbesondere bei Zeilenumbrüchen darauf, dass hier „CR LF“
gesetzt ist und nicht nur ein „LF“, dieses können Sie sehr gut im
Editor wie z.B. Notepad++ prüfen.
Achten Sie auch ferner darauf, dass der Texterkenner “ richtig gesetzt ist!
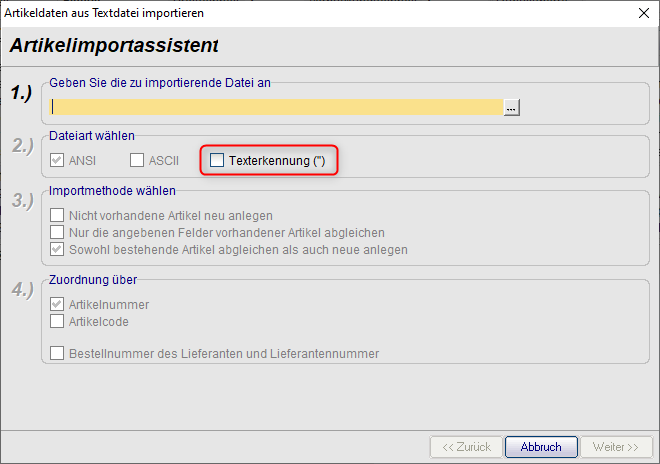
Achten Sie dann insbesondere darauf, dass nachfolgend die „Texterkennung („)“ auch beim Import angehakt ist, hier gibt es keine automatische Erkennung.
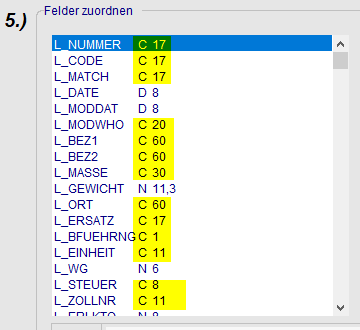
Wenn Texterkennung angehakt wurde, erwarten wir dieses dann für alle Zielspalten (C) und nicht nur für eine Spalte! Achten Sie insbesondere dann darauf, dass z.B. bei Artikelnummern die rein numerisch sind diese auch mit Texterkenner exportiert werden.
Was hat sich bei Bild 1 & 2 geändert?
Bei den Bildern 1&2 haben wir auch eine neue Funktion eingebaut, damit ist es nun möglich automatisch die Bilder 1&2 zu verknüpfen und in unserer dbFakt Umgebung abzuspeichern.
Wir verarbeiten Bilder aus folgenden Formaten:
*.JPG
*.PNG (PNG wird dann in JPG automatisch konvertiert)
Nachfolgendes Beispiel lädt ein Bild von einer URL runter und speichert das Bild in unserer dbFakt Umgebung ab und verknüpft dieses auf Bild 1 beim Artikel 10001
l_nummer;l_idmedia1
10001;https://www.dbfakt.de/bilder/bild10001.jpgNachfolgendes Beispiel lädt ein Bild von einem UNC-Pfad und speichert das Bild in unserer dbFakt Umgebung ab und verknüpft dieses auf Bild 1 beim Artikel 10001
l_nummer;l_idmedia1
10001;\\servername\freigabename\ordner\bild10001.jpgNachfolgendes Beispiel lädt ein Bild von einem absoluten Pfad und speichert das Bild in unserer dbFakt Umgebung ab und verknüpft dieses auf Bild 1 beim Artikel 10001
l_nummer;l_idmedia1
10001;c:\benutzer\downloads\bild10001.jpgWas kann ich tun wenn ich die Felder (Text 1 &2) für was anderes genutzt habe und ich eigentlich nur einen Inhalt dort hinschreiben möchte?
Sie können in diesem Fall nur wie folgt vorgehen:
- Legen Sie sich entsprechende Dateien im Pfad der Artikeltexte an: Pfad für Texte in den Stammdaten
- Weisen Sie nun in der Importdatei diesen absoluten Pfad für Texte in den Stammdaten inkl. des Dateinamens zu
l_nummer;l_txtfile1
10001;c:\dbFaktPro\Texte\textdatei.txt 3. Beim Import wird die Datei gefunden und entsprechend des Dateinamens dann in Text1 oder Text2 beim Artikel geschrieben.